
页面缓存+URL缓存+对象缓存
页面缓存
其实系统访问某个页面的时候,并不是直接使用系统渲染,而是先从缓存中获取找到数据之后就然后返回给客户端,要是没有找到就手动渲染这个模板,渲染完成之后再把数据返回给客户端,同时把数据缓存到redis中。
其实流程很简单:(1)取缓存 (2)手动渲染模板 (3)结果输出
关于手动渲染,官方的介绍是这么说的;
If you use Thymeleaf, you also have a ThymeleafViewResolver named ‘thymeleafViewResolver’. It looks for resources by surrounding the view name with a prefix and suffix. The prefix is spring.thymeleaf.prefix, and the suffix is spring.thymeleaf.suffix. The values of the prefix and suffix default to ‘classpath:/templates/’ and ‘.html’, respectively. You can override ThymeleafViewResolver by providing a bean of the same name.
就是 Thymeleaf,的模板引擎的时候需要用ThymeleafViewResolver来实现资源的渲染,用的时候注入就可以了。
1 | /商品列表页 不返回页面,直接返回HTML的代码 |
这里还踩到一个小坑,取页面信息的SpringWebContext在org.thymeleaf.spring5.context这个包下面已经没有了,被删除了;在org.thymeleaf.spring4.context下面是有的,自己重写了SpringWebContext这个类。为什么非要要重写,我单独写篇博客写一下,更清晰一些。
URL缓存
其实说是URL缓存,真的是有点不太准确哈,其实和页面缓存是一样的
1 | (value = "/to_detail/{goodsId}", produces = "text/html") |
对象缓存
对象缓存其实就是把缓存数据和对象放在缓存中,这样每次访问的时候从缓存中读取就可以了,就相应的减少了读取数据库的次数,从而提高了网站访问的速度 。
上面的页面缓存是设置有有效期的,因为页面信息可能随时会变,一直在缓存中中就页面的信息每次读出来就不一样了,但是对象就不一样了,这个不设置有效期,或者把有效期设置的很长。
这里做个简单的例子,把做秒杀商品的用户对象放在内存中
1 | public SecKillUser getUserById(long id){ |
因为设置缓存中的对象数据永不过期,那有人更新了自己的密码或者用户名或者其他的信息怎么办,缓存也要随着更新,要不然就缓存数据不一致了。
1 | public boolean updatePassword(String token,long id, String formPasswordNew){ |
做了部分优化,测试一下,测试的Linux服务器为1g+4核。
没有优化之前

优化之后

可以看到并发已经上去了,QPS从1267上升到2218了。
页面静态优化 前后端分离
先想一下我们在平常的开发中前后端交互的流程:其实服务端为动态页面作用很单一就是提供了网站需要展示的数据而已,服务端是不会创造一个新页面的。服务端提供的数据的类型也是很统一,要不就是服务端语言提供的基本数据类型例如:字符、数字、日期等等,要不就是复杂点的数据类型例如数组、列表、键值对等等,不过归属服务端的动态页面还需要服务端语言帮助做一件事情,那就是把服务端提供的数据整合到页面里,最终产生一个浏览器可以解析的html网页,这个操作无非就是使用服务端语言可以构造文件的能力构建一个符合要求的html文件而已。不过一个页面里需要动态变化的往往只是其中一部分,所以做服务端的动态页面开发时候我们可以直接写html代码,这些html代码就等于在构造页面展示的模板而已,而模板的空白处则是使用服务端数据填充,因此在java的web开发里视图层技术延生出了Thymeleaf,freemark这样的技术,我们将其称之为模板语言的由来。
由此可见,服务端MVC框架里抢夺的web前端的工作就是抢占了构建html模板的工作,那么我们在设计web前端的MVC框架时候对于和服务端对接这块只需要让服务端保持提供数据的特性即可。从这些论述里我们发现了,其实前端MVC框架要解决的核心问题应该有这两个,它们分别是:
核心问题一:让模板技术交由浏览器来做,让服务端只提供单纯的数据服务。
核心问题二:模板技术交由浏览器来承担,那么页面的动态性体现也就是根据不同的服务端数据进行页面部分刷新来完成的。
而这两个核心问题解决办法那就是使用ajax技术,ajax技术天生就符合解决这些问题的技术手段了。
简答来讲就是其实就是将页面缓存到客户的浏览器上,当用户访问页面的时候,仅从与服务器取数据,从本地缓存中取页面,节省网络流量。
1 | //商品详情页 |
之前我们是把数据通过model.addAttributes()传递给页面的,然后返回的是HTML页面,这里直接就是@ResponseBody,返回的是页面上需要的一些数据,不需要整合把数据整合到页面中。
对应的前端HTML的代码
1 |
|
可以看到这里把html中的原来的依赖于Thymeleaf的部分全部重写,直接从浏览器的缓存中取数据,填充页面。其实还需要做一个配置,就是把application.properties中添加上spring对于静态资源的配置,就是SPRING RESOURCES HANDLING的配置
1 | #static |
这样就完成了前后端的分离。
静态资源优化
代码压缩
最常规的优化手段之一。
我们在平时开发的时候,JS脚本文件和CSS样式文件中的代码,都会依据一定的代码规范(比如javascript-standard-style)来提高项目的可维护性,以及团队之间合作的效率。
但是在项目发布现网后, 这些代码是给客户端(浏览器)识别的,此时代码的命名规范、空格缩进都已没有必要,我们可以使用工具将这些代码进行混淆和压缩,减少静态文件的大小
文件合并
在npm流行的今天,前端在进行项目开发的时候,往往会使用很多第三方代码库,比如jQuery,axios,weixin-js-sdk,lodash,bootstrap等等,每个库都有属于自己的脚本或者样式文件。
按照最老的方式的话,我们会用一些标签分别引入这些库文件,导致在打开一个页面的时候会发起几十个请求,这对于移动端来说是不可接受的。
在减少文件请求数量方面大致有以下三方面:
1、合并js脚本文件
2、合并css样式文件
3、合并css引用的图片,使用sprite雪碧图。
GZip
开启GZip,精简JavaScript,移除重复脚本,图像优化
CDN优化
简介:CDN(内容发布网络),是一个加速用户获取数据的系统;既可以是静态资源,又可以是动态资源,这取决于我们的决策策略。经常大部分视频加速都依赖于CDN,比如优酷,爱奇艺等,据此加速;
原理:CDN部署在距离用户最近的网络节点上,用户上网的时候通过网络运营商(电信,长城等)访问距离用户最近的要给城域网网络地址节点上,然后通过城域网跳到主干网上,主干网则根据访问IP找到访问资源所在服务器,但是,很大一部分内容在上一层节点已经找到,此时不用往下继续查找,直接返回所访问的资源即可,减小了服务器的负担。一般互联网公司都会建立自己的CDN机群或者租用CDN。
这些就了解下原理,毕竟大部分是前端的。
关于这个还找到了一篇博客啊,仅供参考。
https://blog.csdn.net/zhangjs712/article/details/51166748
超卖问题
超发的原因
假设某个抢购场景中,我们一共只有100个商品,在最后一刻,我们已经消耗了99个商品,仅剩最后一个。这个时候,系统发来多个并发请求,这批请求读取到的商品余量都是99个,然后都通过了这一个余量判断,最终导致超发。(同文章前面说的场景)
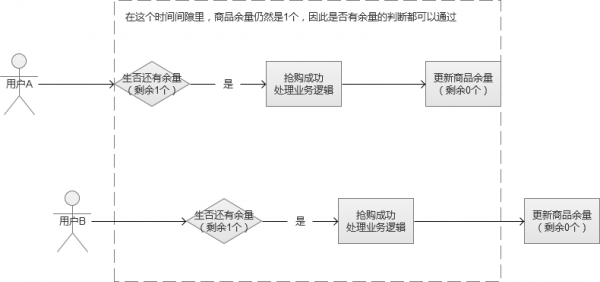
在上面的这个图中,就导致了并发用户B也“抢购成功”,多让一个人获得了商品。这种场景,在高并发的情况下非常容易出现。
1.数据库唯一索引
就是分表,秒杀的订单和正常的订单是两张表,在数据库中建立用户id和商品id的唯一索引,防止用户插入重复的记录。
2. 悲观锁思路
解决线程安全的思路很多,可以从“悲观锁”的方向开始讨论。
悲观锁,也就是在修改数据的时候,采用锁定状态,排斥外部请求的修改。遇到加锁的状态,就必须等待。
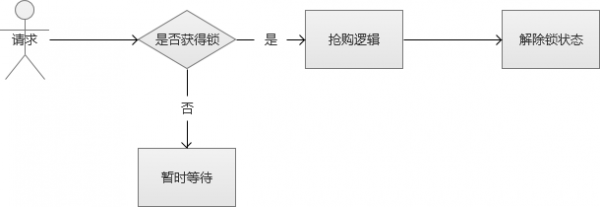
虽然上述的方案的确解决了线程安全的问题,但是,别忘记,我们的场景是“高并发”。也就是说,会很多这样的修改请求,每个请求都需要等待“锁”,某些线程可能永远都没有机会抢到这个“锁”,这种请求就会死在那里。同时,这种请求会很多,瞬间增大系统的平均响应时间,结果是可用连接数被耗尽,系统陷入异常。
3. FIFO队列思路
那好,那么我们稍微修改一下上面的场景,我们直接将请求放入队列中的,采用FIFO(First Input First Output,先进先出),这样的话,我们就不会导致某些请求永远获取不到锁。看到这里,是不是有点强行将多线程变成单线程的感觉哈。
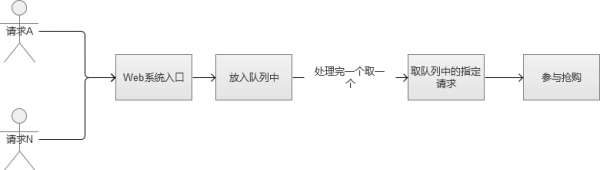
然后,我们现在解决了锁的问题,全部请求采用“先进先出”的队列方式来处理。那么新的问题来了,高并发的场景下,因为请求很多,很可能一瞬间将队列内存“撑爆”,然后系统又陷入到了异常状态。或者设计一个极大的内存队列,也是一种方案,但是,系统处理完一个队列内请求的速度根本无法和疯狂涌入队列中的数目相比。也就是说,队列内的请求会越积累越多,最终Web系统平均响应时候还是会大幅下降,系统还是陷入异常。
4. 乐观锁思路
这个时候,我们就可以讨论一下“乐观锁”的思路了。乐观锁,是相对于“悲观锁”采用更为宽松的加锁机制,大都是采用带版本号(Version)更新。实现就是,这个数据所有请求都有资格去修改,但会获得一个该数据的版本号,只有版本号符合的才能更新成功,其他的返回抢购失败。这样的话,我们就不需要考虑队列的问题,不过,它会增大CPU的计算开销。但是,综合来说,这是一个比较好的解决方案。
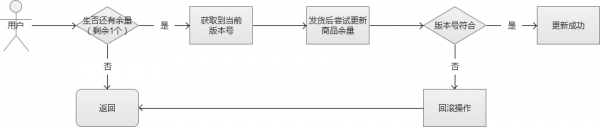
有很多软件和服务都“乐观锁”功能的支持,例如Redis中的watch就是其中之一。通过这个实现,我们保证了数据的安全。
就是采用计数器的方式,用一个集合,存放每个商品以及其对应的数量,如果只是单纯的decr函数或者是incr函数,不能解决秒杀这种问题。因为有可能在并发的情况下,两个请求取到的数都是0,然后都加1,结果为1,实际上应该是2。那么这个时候建议利用乐观锁,实现自己的decr函数。
乐观锁的机制如同版本控制,如果修改的时候,要修改的value在redis中的值已经跟取出来时不一样,则修改失败。