
文献阅读
1 A Framework for Evaluating Mobile App Repackaging Detection Algorithms
- 引用:Huang H, Zhu S, Liu P, et al. A Framework for Evaluating Mobile App Repackaging Detection Algorithms[M]// Trust and Trustworthy Computing. Springer Berlin Heidelberg, 2013:169-186.
1.1 文章中提到的几种方法
DroidMOSS:使用一种称为模糊散列的特殊的散列技术:这种方法是计算每个单元中的dex文件的哈希值,它使用重置点将长操作码序列拆分为小单元,然后将所有散列值连接成一个整体。这种方法的缺点是一个是一些重新打包的情况将大量代码作为噪声插入到原始应用程序中,另一个事实是广告库的不完整白名单,这会在操作码序列中产生大量噪声。这样的计算出的哈希值也就有很大的可能性不一样了。(1-2-3-4 加入噪声之后就是1-2-8-8-6-7-3-4这样的话哈希值就差很多,可能计算出来只有50%的相似度。)同样的罗宾的论文中的基于类目录的方法的缺点也是这样的,也是如果我通过添加一些随机的噪声类,可能不起啥作用,但还是导致hash值变换的很多。
DNADroid:就是将dex文件通过名为dex2jar的工具转换为Jar,这样他们就可以利用WALA [14]计算每种方法的静态数据依赖图(DDG)。 DDG被认为是相似性比较应用程序的主要特征。 DNADroid使用基于图形同构的算法比较预先计算的Android应用程序集群中的DDG。其实就是函数调用或者是变量调用依赖关系图,这种方法的话其实一样的,我可以添加无用的变量来实现让别的函数调用它,其实这段代码不起啥作用。
基于特征哈希的检测:首先是将dex文件根据某些预定义标准进行分组,以减少比较开销,他的特征的选择是:在程序的每个基本块内的各种操作码序列模式的k-gram被认为是特征。例如,他们选择5-gram作为大小为5的移动窗口,它在每个基本块内移动以映射并将特征标记为m位向量。然后将位向量进一步组合成特征度量以指纹每个app。 Juxtapp目前使用各种预定义的操作码序列作为特征。其实就是在代码中发现了(A_B_C_D_E这种形式的时候就把他映射成是一个向量(A是一个实例,B是一个字符串常量,C是一个方法调用这种过程))
还是和上面一样的缺点,噪声代码的注入,怎么办?尽管可以缩小移动窗口的大小,但是这样的话就会提高误报的概率。
1.2 文章给出的评估框架:

第一个组件称为Dalvik Bytecode预处理器,它将Dalvik EXecutable(DEX)分解并转换为中间表示(IR)代码格式。第二个组件是IR Code Obfuscator,它直接用于原始程序的输出IR格式。IR Code Obfuscator试图模仿基于真实世界的混淆重新打包过程。因此,该组件从原始输入dex文件输出一组混淆版本。在此过程中,我们必须确保所有代码操作和混淆操作都是语义保留转换。在混淆之后,IR2Dex Repackager将语义等效的IR代码转换回Dalvik字节码,以便它与大多数检测器兼容,这些检测器将dex文件作为输入。
dx工具用作重打包的工具
接下来的就是介绍每个组件使用不同的工具去实现这个框架,然后通过分析不同的混淆方法来实现这个框架的评估。
2 用于自动Android恶意软件检测的深度神经网络
- 引用:Hou S, Saas A, Chen L, et al. Deep Neural Networks for Automatic Android Malware Detection[C]// Ieee/acm International Conference on Advances in Social Networks Analysis and Mining. ACM, 2017:803-810.
2.1 数据集来源:
Comodo云安全中心的真实样本集
2.2 本文中的方法:
在本文中,基于从smali文件中提取的应用程序编程接口(API)调用的分析,我们进一步将属于smali代码中的某个方法的API调用分类为块。基于生成的API调用块,我们然后探索深度神经网络(即,深度信念网络(DBN)和堆叠自动编码器(SAEs))以用于新未知的Android恶意软件检测。我们不再直接使用API调用,而是进一步对属于smali代码中相同方法的API调用进行分类,形成检测的特征样本。
2.3 提到的其他的方法:
- ‘W. Wu and S. Hung, “Droiddolphin: a dynamic android malware detection framework using big data and machine learning,” in RACS, 2014.’中使用动态分析框架(包括DroidBox 2和APE3)来记录收集的Android应用程序中的13个活动特征,然后应用支持向量机(SVM)构建恶意软件预测模型
- ‘A. U. Z. I. Burguera and S. Nadjm-Tehrani, “Crowdroid: behavior-based malware detection system for android,” in SPSM, 2011.’将API系统调用解压缩为k-means聚类的特征集
- API调用,权限和意图消息作为k-means聚类的输入特征,最后是k-NN分类
- 由API调用和权限请求组成的功能集,然后将它们提供给SVM,决策树和集合分类器。
本文架构
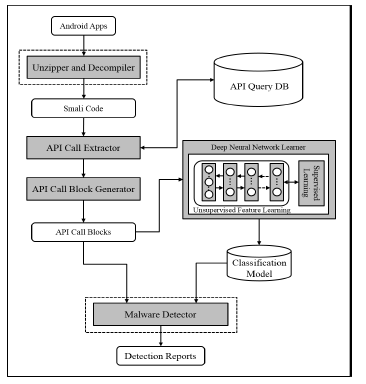
本文中提出的架构如上图所示:
恶意软件检测程序:对于每个新收集的未知Android应用程序,它将首先通过解压缩器和反编译器进行解析以获取smali代码,然后将从smali代码中提取其API调用,最后将生成API调用块作为特征向量。通过使用构建的分类模型,此应用程序将标记为良性或恶意。其实就是把API调用块映射成向量的形式。举个例子(Lorg/apache/http/HttpRequest;!addHeader” —-》<520,506> — >\)
然后就是构建特征集(
$$
D = (x_{i},y_{i})_{i=1}^{n}
$$
x表示API调用块形成的特征向量,y表示对应的程序。
然后将上述数据集放到DBN或者是SAEs中去训练。
要使用SAE进行Android恶意软件检测,需要在顶层添加分类器。
使用反向传播(BP)和基于梯度的优化技术训练SAE深度网络是很简单的,然而,已知以这种方式训练的深度网络具有差的性能。幸运的是,Hinton等人开发的贪婪分层无监督学习算法。 [8]已经克服了这个问题。该算法的关键在于以自下而上的方式逐层预加深深层网络,然后以自上而下的方式应用BP对参数进行微调,从而获得更好的结果。
最后的实验结果是DBN优于SAEs优于浅层的学习模型如DT,SVM等。
3 HyDroid: A Hybrid Approach for Generating API Call Traces from ObfuscatedAndroid Applications for Mobile Security
- 引用:Khanmohammadi K, Hamou-Lhadj A. HyDroid: A Hybrid Approach for Generating API Call Traces from Obfuscated Android Applications for Mobile Security[C]// IEEE International Conference on Software Quality, Reliability and Security. IEEE, 2017:168-175.
在本文中,他给出了一种混合方法HyDroid,它结合了静态和动态分析,从应用程序服务组件的执行中生成API调用跟踪。
使用Jimple grammar将二进制文件转换为更高级别的表示。
系统框架:
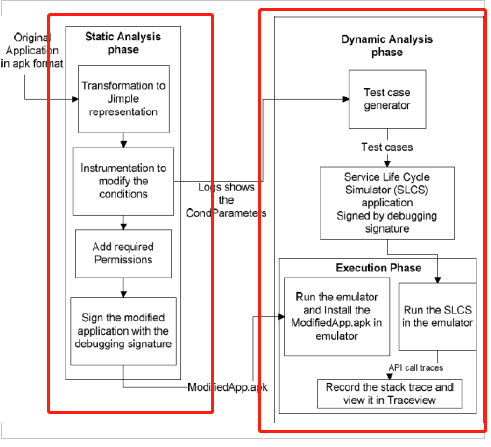
这个方法的检测过程分为两部分:
静态分析部分:
这一部分是通过改变我们通过遍历服务的方法和修改if语句条件来实现程序按照所需的路径运行代码。整个条件由布尔变量替换。其次,赋值语句在if语句体内完成。最后,添加了异常处理。
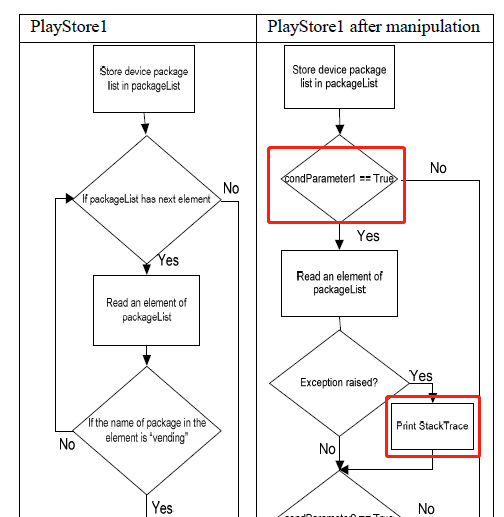
这一部分是通过将反编译的二进制文件准换为Jimple语句,然后通过Jimple语法来实现if条件语句的控制和修改。下面是修改的例子。
- 动态分析部分:
SLCS模拟服务的生命周期,以与测试应用程序中的服务进行交互。在执行的过程中把API的调用的过程找出来。保留Android API调用以及可以揭示恶意软件行为的Java库调用。
缺点:
- Encrvption是另一种强大的混淆技术,可用于代码的不同点,包括字符串加密,整个类的加密或应用程序资源的加密。如前所述,当字符串加密和反射可以一起使用时,我们的方法可以很好地打败字符串加密。如果整个类都是加密的,那么无法解密类的检测是不可能的。即使对于HyDroid来说,这种类型的混淆仍然是一个挑战。
- 加入噪声代码的话会使得这种方法生成不必要的代码来实现API轨迹的调用,这样的话就增加了不必要的负担。
数据集
数据集来自Gnome。
其实这篇文章之研究了服务组件的API,但是有可能恶意代码不插入在服务组件中。
4 SAMADroid: A Novel 3-Level Hybrid MalwareDetection Model for Android Operating System
- 引用:Arshad S, Shah M A, Wahid A, et al. SAMADroid: A Novel 3-Level Hybrid Malware Detection Model for Android Operating System[J]. IEEE Access, 2018, PP(99):1-1.
4.1 概述
这篇文章说给出了新的三层混合Android恶意软件检测模型,命名为SAMADroid。它是恶意软件分析和检测的三个级别之间的混合:(1)静态和动态分析;(2) 本地和远程主机;(3)机器学习情报
先给出来一篇论文中使用的AASandbox来进行的静态和动态相结合的恶意软件分析;然后又介绍了另一个方法DroidRanger:分两步:(1)它使用恶意软件执行预期功能所需的基本权限来过滤恶意应用程序(我觉得没啥用,因为权限的话有一些正常的软件也会有一些过分的权限需要);(2)记录API调用及其参数,以便检测动态加载的Java代码的恶意行为。
接下来还有些别的文献的方法,基本上分为两种吧:
- 基于机器学习的恶意软件检测,有各种各样的特征提取方法,包括静态分析或者是动态分析提取的特征,然后进行分类。
- 基于本机和主机的分析:其实就是现在本机通过一定的方法进行本机的检测,然后将认定为有风险的APP通过收集APP的应用信息传到主机上进行分析或者是直接将APK传到服务器上进行详细的分析。
4.2 本文的框架
本文中的方法是一个3层的检测模型
- 静态和动态结合分析
分析的静态的功能:API,权限,组件,请求的硬件,意图过滤器(使用到的工具是Android Asset Packaging Tool和Baksmali)
动态调用:安装应用并对系统调用跟踪进行分析(具体的是分析啥?这里没说,看看下面)
这一级的模型是他开发了一个安卓的客户端,然后对和网络还有文件操作相关的系统调用进行了跟踪。
本机和主机分析:这里的本机和主机分析其实是在本机上不执行检测,只执行安装然后跟踪系统调用日志然后上传到服务器进行仔细的静态分析过程。
主机分析的过程其实就是根据客户端传来的应用程序的标识符来在本地库中选取APK或者是从应用商店下载来执行静态分析
机器学习分析:在服务器上进行分析(特征向量的构建来自于上面收集的静态数据)。
静态的特征用一个集合表示包括6个子特征集合(如API,硬件,组件这一些),每个维度用0或者1表示,动态的特征就是应用的系统调用频率包括系统文件和网络功能的调用(一共10个特征)(文章里说恶意应用的系统调用频率更高(???))。然后使用SVM进行分类。而且他是静态分析得出一个结果,然后动态分析得出一个结果,两个结果相互印证。
评价指标就是用真阳性率,误报率和准确度来评价。
4.3 工具
- Drebin:Drebin是一个静态分析恶意软件检测框架,可以提取应用程序行为的最大和有用信息的特征。
- Monkey:用于动态的随机模拟用户操作应用程序的过程,用于动态过程
- AASandbox:放置在内核中运行程序通过使用劫持系统来获取程序的运行日志然后构成分析的向量。
- Cuckoo恶意软件分析器用于通过执行应用程序进行动态特征提取
- LIBSVM:A Library for Support Vector Machines:获取地址:http://www.csie.ntu.edu.tw/~cjlin/libsvm/
- ……等等
5 Detection of repackaged Android applications based on Apps Permissions
- 引用:Nisha, O. S. Jannath, and S. M. S. Bhanu. “Detection of repackaged Android applications based on Apps Permissions.” International Conference on Recent Advances in Information Technology 2018:1-8.
5.1 基本概念
- 每个Android应用程序由四个组件组成:
- 活动:单个屏幕侧重于用户操作。
- 服务:为应用程序执行后台服务。
- 广播接收器:从操作系统和应用程序中侦听消息。
- 内容提供商:定义数据库存储。
这些组件可以使用Intent消息在彼此之间进行通信。这些组件在“AndroidMani-fest.xml”文件中声明,该文件描述了每个组件的生命周期以及它们如何通信。
- 安卓的安全机制:沙箱和权限(开发人员必须要显式的声明)
5.2 本文的研究内容
这篇文章其实也是用机器学习的方法来检测恶意程序的,在选择特征的时候他使用了一些特征的选择方法如卡方检验(基于统计的一种方法),MI(相互信息)来选择特定的特征,对于特征加权的时候使用术语频率法和特征排序法。术语频率方法估计文件中术语的频率,仅适用于中英文信息检索。特征排序方法基于统计和信息理论来度量特征和类变量的相关性。提取完特征之后使用分类算法来对恶意和良性应用进行分类。
架构如下:
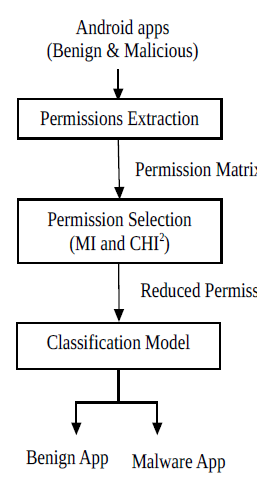
最后就是对几种不同的分类算法得到的结果进行了比较。
代码混淆工具
- SandMarks
- Zelix KlassMaster
方法和API调用轨迹生成工具
- soot-infoflow-android
- APIMonitor
静态分析工具
- Androguard
想法
- 我给APK文件中的某一些程序加密的时候随机选择这个程序中的某一个文件的hash值作为一部分秘钥。然后这样的话他是可以知道hash值是不假,但是要是全部弄出来的话增加了难度。而且我每个的方法的名字也给他命名的不一样吗,随机用字符串来做命名。从我的某一个字符串库中,或者直接就是去hash值,或者是我随意命名。
- 机器学习的分类:就是需要找到大样本集,然后找到合适的特征:API的调用,类目录,方法调用,权限使用等等(可以使用动态和静态方法结合的方式来提取特征,也就是通过找到动态特征向量和静态特征向量来训练模型),然后选择合适的分类器,这里的话就是看自己的选择了。其实动态特征和静态特征的提取工具有很多,可以参考文章4,里面介绍了很多的方法。
- 其实现在的检测的主要的方法还是基于相似性的检测,还有一部分是机器学习的检测,动态检测和自我防御。