
文献阅读整理 20181013
1. SPRD:基于应用UI 和程序依赖图的Android 重打包应用快速检测方法
1.1 文章的内容
这篇文章中说研究发现重打包应用通常不修改应用用户交互界面(UI, user interface)的结构,提出一种基于应用UI和程序代码的两阶段检测方法。首先,设计了一种基于UI 抽象表示的散列快速相似性检测方法,识别UI 相似的可疑重打包应用;然后,使用程序依赖图作为应用特征表示,实现细粒度、精准的代码克隆检测。
重打包静态检测一般会遇到的问题:在Android 应用程序静态分析中,通常会受到第三方的库文件和代码混淆的影响。
本文的研究的框架:
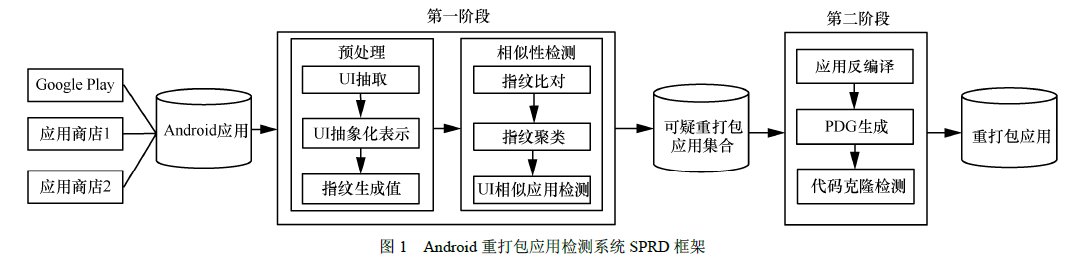
检测的过程:
第一阶段应用UI 的快速相似性比较步骤主要分为预处理和相似性检测这2 个部分,在预处理中,首先抽取Android 应用的UI,将UI 中每一个视图(view)生成一种抽象化的表示,并使用散列算法生成view 的唯一指纹值;在相似性检测部分将每一个应用的view 指纹值进行比对,并将指纹值相同的view 做聚类处理,找出UI 相似的应用,输出可疑的重打包应用集合。
在第二阶段程序代码的细粒度克隆检测中,首先,反编译在第一阶段中输出的可疑重打包应用,生成每一个应用的PDG 作为其特征表示,利用图的相似性比较算法实现程序代码的克隆检测。最后,根据上述2 个阶段计算得出的相似值进行综合判定完成重打包应用的检测。
映射的具体规则:
表示为A=(I, D),I表示UI,D表示code。
其中Android 应用UI 表示为
$$
I=\{V_{i}\},i=1,2,3,…,n
$$
其中
$$
V = <L,C, \Phi >
$$
L 和C 分别表示布局和组件集合,Φ 表示布局和组件之间的包含关系。
应用程序依赖图表示为
$$
G=<S, E>
$$
其中,S 表示函数的语句集,E 表示边集,当语句之间有数据或控制依赖时,语句之间存在有向边连接。
提取UI应用的过程:UI 的基本组成单元是view,抽取了view的结构,然后进行的映射
抽象表示:

其指纹的三元组表示为<length,hash_value, app_id>。其中,length 为线性抽象表示
字符串的长度, hash_value 表示字符串的散列值,app_id 表示为应用程序的ID。
UI的相似性检测:
将上面的三元组存放在字典中,key为length 。
依次遍历字典DIC 的键,针对DIC 中相同键值的列表,将列表中抽象表示字符串的散列值进行两两相似性比较。如果值相同,则检测出相似的应用view。在得到存在view 相似的应用后,通过分析2 个应用中所有的view 相似比例来度量应用UI 的相似性,从而判定其是否为一对可疑的重打包应用。
代码相似性检测:
PDG 主要用于表示程序函数体中语句之间的依赖关系,包括数据依赖和控制依赖等。
2. Effective and Scalable Repackaged Application Detection based on User Interface
在本文中,我们提出了一种基于静态UI特征的大规模检测的高效简单方法。所提出的方法包括粗粒度检测以通过比较图像哈希来选择可疑的重新包装的应用,以及细粒度检测以执行更详细的UI比较以通过使用熵比较布局来细化结果。此外,我们提出了一种动态选择方法来选择可疑应用程序,这比固定阈值更准确和有效。
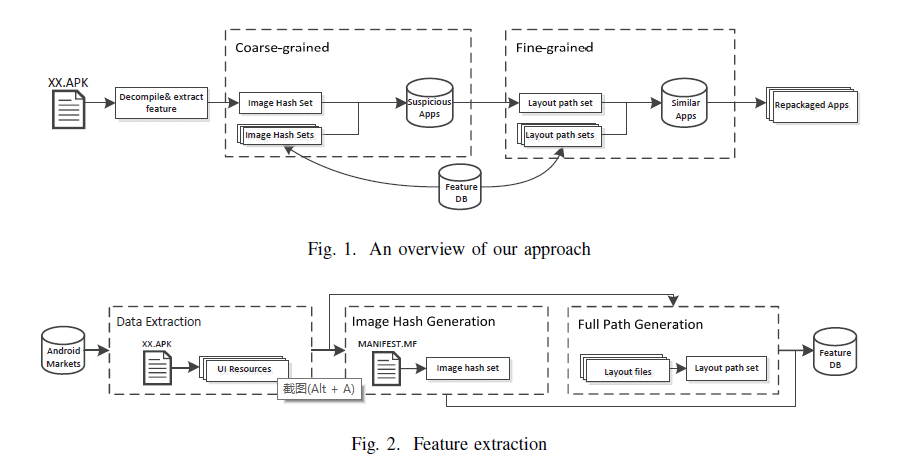
粗粒度分析:
我们直接从文件MANIFEST.MF中提取它们,这样更简单,更快捷。(在apk签名过程中生成MANIFEST.MF并存储所有资源文件的摘要哈希值)。
通过比较图像哈希值的相似性先找到可疑的相似应用,然后在进行细粒度的分析。
动态阈值的选择过程:
首先统计我们获得相似值分布为0.1,0.3和0.8,最大间隙位于0.3和0.8之间。其次,大多数重新包装的应用程序对的相似度值分布在最大差距之上,并且大多数非重新打包应用程序对的相似度值低于它。对于相似度大于这些值的就直接不考虑他们之间的相似性了。
细粒度分析:
我们需要首先将所有引用的布局文件合并到一个文件(怎么合的也不说,感觉用程序来合并的话有一定的难度,暂时没啥想法,遍历嘛?????,手动的话就滑稽了!!!),然后提取UI的树形结构,形成特征值。其实和第一篇文章应该差不多,但是这里面没有具体说。
然后使用基于熵的相似度算法来进行相似性的比较。
说实话这篇文章还是挺有意思的,因为这里把UI作为了细粒度的分析特征,但是上面的文章就把UI特征提取作为粗粒度的特征。
3. A Deep Learning Approach to Android Malware Feature Learning and Detection
这篇文章是恶意软件检测方法
在本文中,我们介绍了DroidDeep,这是一种针对Android恶意软件检测的深度学习方法,它考虑了多个级别的功能,以解决上述研究工作的局限性。DroidDeep首先考虑静态信息,包括权限,API调用和组件部署,以表征Android应用程序的行为模式,并从Android应用程序中提取包含超过30,000个功能的多级功能集。然后,我们将这些提取的特征提供给深度学习模型,以学习分类的典型特征。最后,我们将学到的特征放入基于支持向量机算法
(SVM)的检测器中,用于检测Android恶意软件。
对于这里面选择的特征集太多了导致计算资源的开销,为了解决这个问题,我们使用深度信念网(DBN),这是一种快速,贪婪的学习算法,能够学习典型特征并减少提取特征的数量以节省计算资源。
文章中说几乎没有误报,我觉得嗯,吹牛,机器学习的方的通病就是在自己收集的数据集上效果非常好,但是换一个数据集的话效果就不可能那么好了。
还有就是浅层的网络结构(少于两层的网络)解决约束良好的简单问题时很好,但是复杂问题的时候就不能够有很好的代表性。
框架:
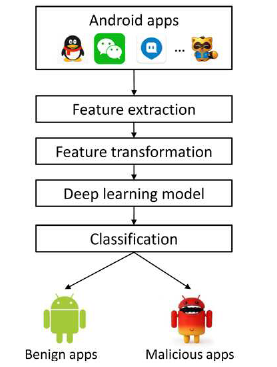
然后深度学习的框架如下图所示:
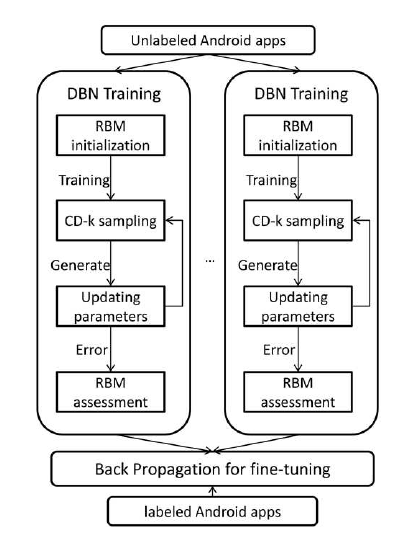
训练完成之后使用SVM分类算法对收集到的数据集进行分类,最后在这一组数据集上的分类准确率为97.5%。
在一组未知的数据集上准确率为92.2%(这种数据集是由VirusTotal来评估的)。
4. DAPASA: Detecting Android Piggybacked Apps Through Sensitive Subgraph Analysis
4.1 文章内容
这一篇文章也是恶意软件检测方法,因为文章写的很详细,而且有些可以可以借鉴的地方,所以看一下。但是比较难。
本文成立的两个假设:
- 恶意应用会请求更加敏感的权限。
- Generally, in the rider, the cohesion of sensitive APIs, which is measured by calling distances, is higher than that in the carrier
为了区分敏感API的恶意程度,使用类似于TF-IDF来定义API的敏感性。它可以减少在良性和恶意应用程序中经常出现的敏感API的干扰因素。因为良性的应用有的时候也会请求一些敏感的权限。所以避免这些对于检测的干扰还是很重要的。
我们构造了一个敏感的子图来表示整个调用图并描述给定应用程序的最可疑行为。并从子图中提取了5个特征。这个敏感子图是可以代表整个函数调用图的。因为直接比较图的相似性需要很高的开销。子图的话就好一些。而且他从子图中再寻找API灵敏度最高的最高的子图作为分析的特征。
DAPASA架构:

计算灵敏度系数以表示敏感API在执行恶意行为时的恶意程度。敏感API的灵敏系数是基于统计意义的,就是统计API在恶意应用中和良性应用中出现和使用的次数然后使用一个公式来度量这个敏感系数。而且并不是使用的频率越高灵敏度越高,他是恶性和良性中都使用的很高的时候比那个恶性中使用高而在良性中使用低的API的灵敏度要低。
然后就是从应用依赖图中构建子图,构建子图的过程中其实就是计算节点之间的距离,然后生成子图,。对于每个敏感API节点,将在SFCG中构建其子节点及其相邻节点。在计算两个节点之间的距离时,SFCG被视为无向图。在我们的工作中,SFCG的平均最短路径长度通常为3到5.构建子图时,正常节点到敏感API节点的距离小于或等于2。 不知道距离是怎么来的,可能生成SFCG的时候就有?????
然后从子图中找灵敏系数最高的子图的时候,使用了类似于最小生成树的算法,因为就是已经给他计算出了每个节点的灵敏度系数,然后你就找到哪些子图的包含的节点是具有最高的灵敏度系数。(一个特征)
然后为了证明这个敏感系数和敏感距离是可以使用的区分特征,使用统计的方法分析了恶意应用中的敏感系数是大于良性应用的。(一个特征)
对于灵敏度最高的子图中他以三节点为单位统计三节点出现的频率,敏感图案在本文中被定义为包含至少一个敏感API节点的重要图案。这样就又把一些没有用的去除了,为了验证正确性买还是基于统计的方法来验证是不是就是在搭载应用中这种结构出现的频率比良性应用中出现的高。(三种视图三个特征)
在最后就是使用分类器来对应用进行分类。
数据集:Android Malware Genome Project(一般是作为基准来做的)
4.2文章中提到的值得注意的方法、
RepDetector的基于语义的方法,它首先在应用程序中提取核心功能的输入输出状态,然后比较功能和应用程序之间的相似性。RepDetector对依赖于每个应用程序的语义分析而不是语法特征的混淆攻击具有很强的鲁棒性。
动态方法的缺陷:但是,大多数动态分析方法需要一组有代表性的执行路径,并且很难确保可以覆盖应用程序的所有执行路径。
5. Semantics-Based Repackaging Detection for Mobile Apps 值得仔细看下细粒度分析
本文的方法是提出了一种基于语义的检测方法,通过捕获函数的输入 - 输出关系以表达其语义。只要重新打包的应用程序保留了原始应用程序的关键语义,相似性就会很高。
本文的研究框架:

RepDetector由四个主要模块组成:核心类和功能提取,功能输出状态构造,功能相似性测量和应用程序相似性测量。核心功能以及重要的类将根据应用程序的字节码和清单文件提取。然后,我们为这些核心函数构造状态流图,并计算每个函数的输出状态。使用可满足模数理论(SMT)求解器,然后我们根据它们的输出状态检查两个核心函数的语义等价性。最后,我们使用Mahalanobis距离量化两个应用程序(每个应用程序由一些核心功能组成)之间的相似性。我们的方法使用符号执行,但通过合并流状态可以简化计算。
并非所有类都与应用程序的核心功能相关,而重新打包则保留了应用程序的核心功能。因此,对于重新打包检测,我们只考虑与功能相关的类。
核心类和函数提取:清单文件(AndroidManifest.xml)向Android系统提供有关应用程序的基本信息。功能相关的类包括一个应用程序的主要组成部分:
- activities(< activity >)
- services (< service >)
- broadcast receivers (< receiver >)
- content providers (< provider >).
提取的时候只需要提取这些类和功能函数就可以了。减少工作量并且相当于变相去噪声。
通过解析AndroidManifest.xml文件直接检索这些类的列表。然后为类列表构造类调用图(CIG)。
在CIG中,每个节点表示一个类,两个节点之间的有向边表示它们之间存在函数(即方法)调用关系。我们的CIG通过静态分析考虑了类关系和函数调用。此外,我们根据几个属性(例如,CIG中类节点的扇入和扇出)计算CIG中每个类的权重。通过设置权重阈值,我们可以过滤掉权重低于阈值的类。其余的类称为核心类.
然后找输出语义的结构:通过状态流程图(SFC)分析这些核心功能的结构,一个SFC的结构如下图所示:
包括一个初始化块(变量初始化),两个约束(if),5组语句
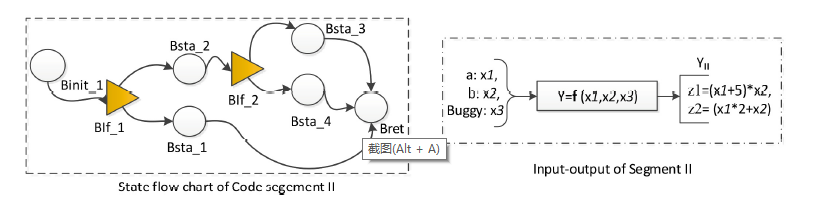
定义的输入输出就和右边的图所示:
在文章中举了一个例子,就是实现相同功能的两个函数,一个有噪声,一个没有噪声,最后的输出是相同的。
两个函数的等价性测量具体的实现:
在其核心功能之间执行成对相似性度量,由于不知道是怎么实现的,所以就需要成对的去比较。对于上面的图输入输出的等价关系是:
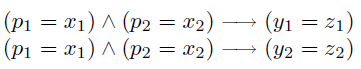
匹配输入的时候是通过将输入抽象成为整数或者是布尔变量,这样容易导致误报。但是这样的处理也简化了使用SMT检查相似性的准确度和速度。
最后是综合所有的核心函数的相似性得分形成一个矩阵,利用矩阵的相似性给出一个判定的标准。
缺点:
这篇文章分析的足够细粒度,但是缺点就是太细了,计算复杂度非常高。应用之间需要相互比较,然后比较的还是成对比较核心函数的功能,就是两组的成对比较,太费资源了。而且他的通过这种语义的比较在语义的生成过程中还有粗粒度的一些做法,感觉不太好。还有就是我添加一些仿照函数,还有把几个函数合并到一起他都不能解决。
最后分析了自己的执行效率,比Androguard这个方法要快。
6. 一种静态Android重打包恶意应用检测方法(大体看了看)
这篇文章对应用之间相似性检测使用了1种基于质心的检测算法,把函数的控制流程图都映射成为一种质心,然后比较质心的相似性。
把二维的程序控制流程图先映射成为3D的,求出一个质心来,
然后通过API(就是语句里面有没有invoke语句)来给每个边赋值权重,再重新求一个质心,通过这两个质心的相似性来确定重打包的恶意应用。加权的方法是通过层次分析法来实现的。加权之后那些数量少但是更加敏感的API就能够更加的突出。
本文的框架如下: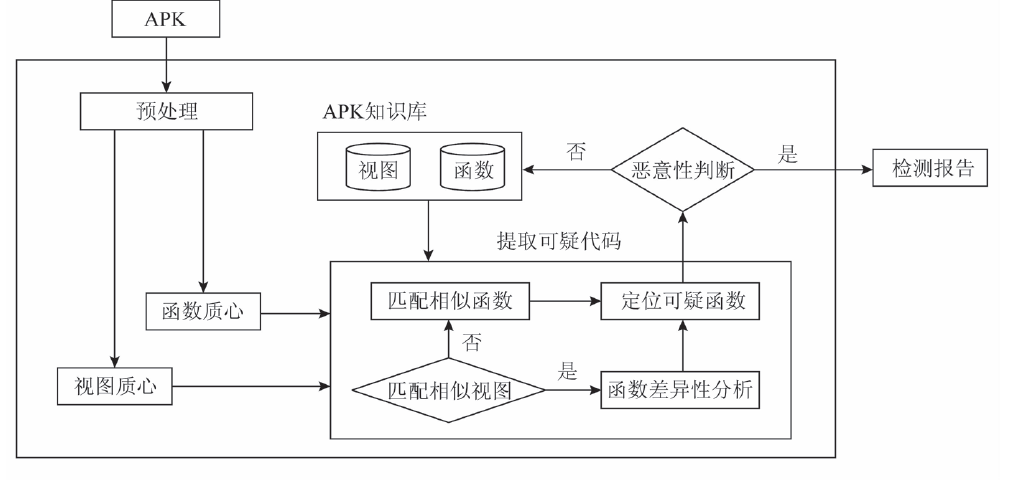
7. DeepRD:基于Siamese LSTM 网络的Android 重打包应用检测方法
本文提出一种基于深度学习的Android 重打包应用检测方法,借助于深度学习强大的特征学习能力[19],自动地学习应用的程序代码特征,通过程序代码的相似性度量实现重打包应用的检测.
本文提出将应用函数作为分析与检测的基本单元,应用函数被表示成序列特征形式并进行向量化处理,然后输入具有LSTM的Siamese 网络中学习程序代码的语义特征,最后通过应用程序代码的相似性度量判断是否为重打包应用。
特征的选取:本文中应用函数的序列特征及特征向量表示方法如下:首先,获取应用函数中API 的调用序列以及与API 存在数据依赖关系的上下文信息形成应用函数的序列特征;然后,将应用函数的序列特征表示成抽象字符串形式;最后,使用词向量嵌入模型将抽象字符串表示成向量形式输入深度学习模型Siamese LSTM 网络中训练。
在程序代码的相似性度量中,本文使用2个LSTM 网络自动地学习程序代码的序列特征表示,利用Siamese 网络度量程序代码的相似性。Siamese 网络是一种应用广泛的特征相似性度量方法。Siamese 网络常用于解决标签样本缺乏情况下的模型训练问题,它通过从数据中学习样本的相似性度量,然后与未知的标签样本进行比较。
数据集:公开数据集AndroZoo。
ZHOU W, ZHOU Y J, GRACE M, et al. Fast, scalable detection ofpiggybacked mobile applications[C]//The Third ACM Conference onData and Application Security and Privacy. 2013: 185-196.
文献中发现重打包应用中加载的恶意组件不是应用的核心代码,使用基于PDG 的模块解耦技术将应用程序代码分为核心模块和非核心代码,设计了一种特征指纹技术抽取核心模块的语义特征,实现重打包应用的检测。现在一般的使用程序依赖图的都是不管核心不核心的,全部要用来生成PDG。
本文的检测框架如下图示:
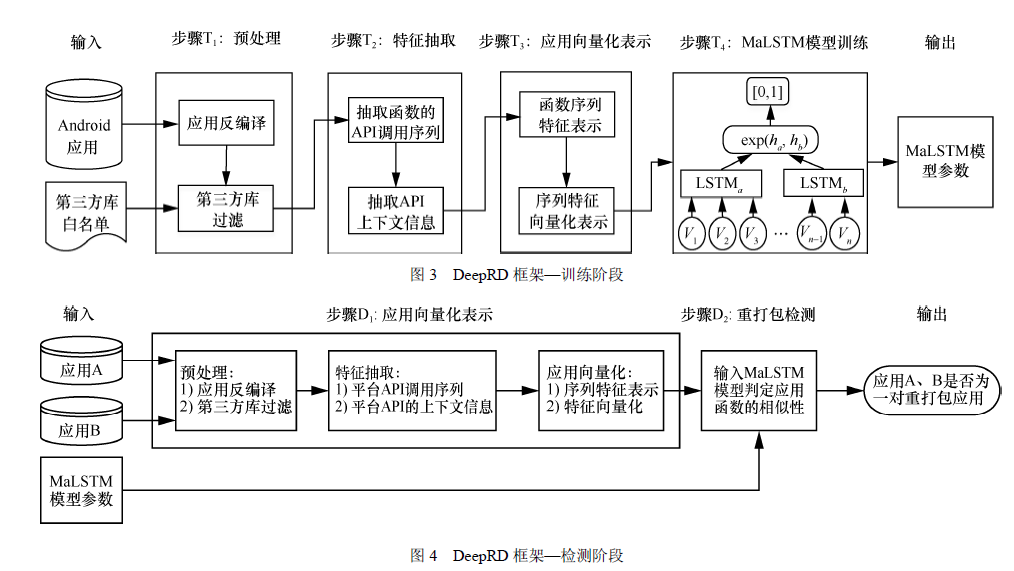
本文API 的上下文信息是指与API 在函数体中存在数据依赖的语句,这里的数据依赖包括前向数据依赖和后向数据依赖这2 种。本文平台API 及其上下文信息表示为一个三元组的形式,即V=<S_prior, S, S_post>。特征集F=(V1,V2,…,Vi,…,Vt)
特征向量化:
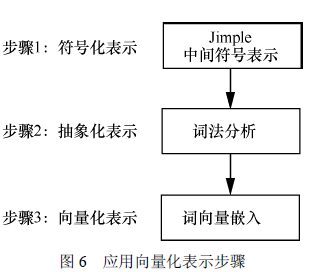
每个函数的特征向量长度不同,本文使用MaLSTM 模型处理变长的序列特征数据。
训练模型的输入是将生成的特征向量及其对应的标签作为模型的输入。其中,标签是指一对特征向量的相似度。
本文基于应用函数相似性度量的重打包应用检测中,需要考虑以下2 个因素:①应用中相似函数的个数或比例;②相似应用函数的规模。给出了度量公式。
最后通过实验与SPRD进行了检测性能的比较,然后就是对自己定义的特征的有效性进行了比较。
8. Fast, Scalable Detection of “Piggybacked” Mobile Applications(可以返回来再仔细看看)
本文 的研究方法是研究的是Piggybacked这一种重打包的应用,搭载应用程序是重新打包的应用程序的一个子集。
本文中提出线性搜索算法(具有O(n log n)时间复杂度)以有效且可扩展地检测搭载的应用程序。
我们的方法基于两个主要观察。首先,在搭载应用程序中,注入代码相对独立,并且不与主机应用程序的主要功能紧密交织(如果有的话)。因此,我们提出了一种称为模块解耦的技术,以将应用程序代码有效地划分为主要和非主要模块。每个应用程序都有一个唯一的主模块,主要实现广告功能。同时,它可能有许多相对独立的非主要模块。各种支持例程或库,广告包和移动支付框架 - 以及嵌入式注入代码 - 都属于这一类。
其次搭载应用程序通常与原始运营商应用程序共享相同的主要模块。因此,我们提出另一种称为特征指纹识别的技术来提取主要模块中包含的某些语义特征(例如,所请求的许可和使用的Android API)。我们将它们表示为特征向量,将这些特征向量组织到度量空间中,然后提出线性搜索算法(具有O(n log n)时间复杂度 - 与之前的O( n2)成对比较的复杂性相比)来检测搭载的应用程序。O(n2)是指映射完特征之后按照最近邻进行比较。但是我觉得要搜索最近邻的话也是需要n!次比较。
本文的框架:
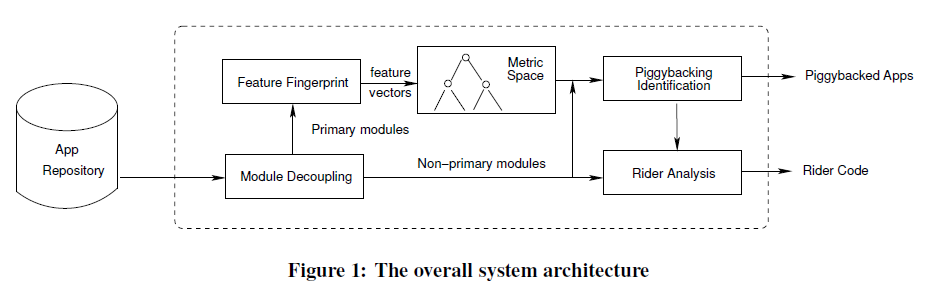
本文成立的假设:我们假设捎带主要通过将Java代码添加到合法应用程序而不是本机代码来实现。考虑到本研究中使用的数据集,我们发现只有5%的应用程序包含本机代码。此外,我们假设合法的应用开发者不会向他人透露他们的私钥(用于app签名)。因此,搭载的应用程序将不会与原始应用程序共享相同的证书。
首先,基于Dalvik字节码,我们构建了一个程序依赖图(PDG),然后根据类的继承关系,函数调用关系,package homogeny和数据依赖关系来对PDG的每条边分配权重。(在生成图形时,我们将权重10,10,2,1分别分配给表示类继承,包同质,方法调用和成员字段引用的边。)两个类包之间的权重很高的话就合并成一个模块。这样程序的模块就分析完成。我们利用AndroidManifest.xml文件中的信息来声明应用程序的各种组件,包括其活动,服务,接收器和内容提供程序。具体来说,它指定将被调用以处理某些事件或操作的具体类。一个特殊的ACTION.MAIN代表应用程序的主要入口点。因此,我们选择包含此类的模块作为主模块的候选者。请注意主模块倾向于为用户提供与之交互的主界面。因此,我们还选择具有处理大多数活动的类的模块作为主要模块候选。候选者很多的时候,我们通过计算清单文件中模块名称与应用程序名称的相似性来选择最相似的候选者。
找到主模块之后,为了使主模块能够将代表APP,并且找到特征指纹将一个主模块的功能与另一个主模块的功能区分开,提取语义功能作为特征也就是权限API这些东西。我们然后将它们表示为向量,其中0和1分别表示主模块中某些特征的缺失和存在。之后,我们将这些特征向量(每个代表一个应用程序)组织到度量空间中,并将检测到搭载应用程序的问题转换为最近邻居搜索问题。用于最近邻居搜索的简单方法是执行成对比较并选择具有最小距离的比较。通过利用其三角不等式属性[43],我们可以在搜索期间有效地修剪不相关的部分并实现O(n log n)时间复杂度。使用三角形不等式属性在构造的VPT树(表征特征向量的)中实现有效的搜索修剪。关于这一部分没太看懂。
关于查看哪些是搭载了应用的应用,文章中说如果应用程序A的非主要模块是B的严格子集,则B中的任何非主要模块(但不是A中的非主要模块)将被视为搭载代码的一部分。因此,我们将应用程序标记为搭载应用程序的应用程序。
想法
- 恶意软件的范围大还是重打包范围大?我感觉重打包的话不一定是恶意的,恶意的也不一定是重打包。应该是有交叉的。恶意应用的话是可以通过机器学习分类的方法解决的,因为只需要分类就可以了,两个类别,恶意和非恶意的,恶意的一般是有特点的,比如获取敏感的权限这样子的。但是重打包的话不是这样子的,重打包的话一般是没有很好的特征,一般是基于两个应用之间的相似程度来分析的。相似的话就定义为重打包的,一般是需要两两比对的
- 一个框架,首先执行大致的聚类分析,相似的应用分为一类(关于具体的特征提取,提取的过多的话额外开销,然后特征过少的话就分类的效果很差,取几个重要的特征如API,权限和组件,然后就是向量化的表示的过程,这个过程是有问题的,怎么样将特征抽象成向量然后向量需要保持特征的语义和信息,相似的很相似,不相似的就差别较大,。这个地方可以参考文章8),而且这个也不是一个学习的过程,然后对聚为一类的执行细粒度分析。通过这种方案的话能够减少两两比较的数量,因为两两比较的话只需要比较聚为一类的应用,大大减少了比较的数量。关于细粒度的比较的话还是需要再看看文章,有什么好的方案。最后的效果怎么样就得看实现之后的效果了,关键的问题在于分类边界的问题。怎么去处理分类边界的问题。就是说两个边界上的点也有可能是重打包的应用(就是说要不要处理边界问题就是看分类的效果了。)还有就是初始聚类种类的设计,实在不行的话可以讨论一下聚类的类别对于检测的影响程度。
- 对于上面的想法,就是使用类似于最近邻的搜索方法,就是画一个圆,只比较每一个特征圆内的所有的APP,比较次数也减少了。对于23这两种是以后看文章的重点,并且关键和重点也是难点在于向量的抽象怎么抽象?关系到检测的准确性。这样的话其实还是和两两比较是一样的。可以看看近似最近邻检索这种方式,这个方法就是在牺牲精度的基础上去返回所有可能是最近邻的点。或者是先分区在搜索。就是把所有的特征分区。分完区之后呢,搜索一个点的近邻,就是如果一个点到一个分区的核心点的距离减去半径大于你所定义的阈值的时候这个分区可以直接不用计算。这两个分区可以直接忽略比较了。还是再想想,这个想法太多漏洞了。
- 如果上面的方法要是不好用,还可以提取出特征来之后使用深度学习的方式去训练模型,通过机器学习的分类只是来分析恶意软件和良性软件的,能够将良性软件和恶意软件分类,但是对于重打包来说,重打包的程序不一定是恶意的,而且通机器学习的分类能够分类出重打包和非重打包的嘛?感觉机器学习和深度学习的方式都是用来分类恶意软件得,因为恶意的软件一定会添加恶意的组件或者是调用恶意的权限。
- 对权限进行排名也是一种很好的方式,这样的话可以避免某些请求频率低的权限的影响,因为要是重打包的应用程序可能会添加更多的权限调用,但是这个权限的调用只用了一两次。
参考文章:W. Wang, X. Wang, D. Feng, J. Liu, Z. Han, and X. Zhang, “Exploring permission-induced risk in Android applications for malicious application detection,” IEEE Trans. Inf. Forensics Security, vol. 9, no. 11,pp. 1869–1882, Nov. 2014.
- 程序依赖图中能不能去燥,比如某些个只调用了一次或者是只出现了一次的调用?或者是类的调用也可以啊,就是每一个对象会new很多次的,只实例化了一次的那种直接给他去除,认定为是噪声代码。?????关于去噪声的方法我觉得可以参考下文章4,他里面就是寻找了最主要的特征。
- 设计一个系统先粗粒度,然后细粒度检测,细粒度检测一般比较耗时间,粗粒度检测完成之后只需要检测粗粒度判定为可疑的应用即可。这样的话其实就是减少了一部分的细粒度的检测时间。具体粗粒度的检测方法是用什么还有细粒度用什么还得具体去考虑。
- 程序依赖图的话可以只分析某一些函数,比如说使用了API的,使用了组件的,使用了权限的,使用了其他的一些,因为他添加噪声代码的话一般是添加无用的代码,因为要是添加一些组件什么的肯定会导致成本增加,而且会导致程序运行的问题和程序的不相似性。还有就是可以分析UI函数的依赖关系图,因为要是为了保持重打包的吸引性,外观一般不会改变很大。其实也就是说分析其核心函数的调用依赖,核心函数怎么定义的呢,就是系统关键部分的东西,同时去除第三方库和Android库。这个第三方库影响很大的,因为有一些很小的软件自己的代码可能很少,绝大部分都是第三方库的,这样的话太容易误判了。罗宾的那篇文章中的第一个基于目录的方式就是那样子的,没有过滤第三方库。
- 分析完成之后,看一下漏报的应用的特征,是不是都是具有一类或几类典型特征的应用被漏报或者是误报了,然后返回来优化自己的模型。
工具
- Pscout:敏感权限获取
- LibD第三方广告库名单软件,并且有手动验证过准确性。